
Amazon Similarity Explorer
new search | design
| data | results
This page briefly describes the design of the Amazon Similarity Explorer (ASE), covering the components, architecture, and algorithms, and ends with some restrictions and limitations.
1. Components
ASE is constructed with open source web development tools. It uses a MySQL database as a back-end data store for intermediate and final search results. Application logic is written in PHP. The front-end is a standard web browser. It is hosted on a FreeBSD system running the Apache web server.
The Amazon database is accessed through Amazon Web Services (AWS) application programming interface. Amazon's Web Services home page is http://associates.amazon.com/exec/panama/associates/ntg/browse/-/1067662/102-8627506-9944939 (Amazon, 2003)
The PHP modules to use the web services were provided by Filzhut. A full description of the Filzhut API is available at http://hray.com/5703/a1/amazon_functions/documentation/ (Filzhut, 2003)
2. Architecture
A standard three tier web architecture is employed, with the browser front-end, PHP application layer, and MySQL database.
Three PHP modules provide the programming framework. "input.php" processes initial capture of search criteria. "showsearch.php" contains the logic to display archived search results. "amazon.php" contains the bulk of the application, containing the code that builds both the similarities list and the personal web.
A very simple database is used. One table stores the input parameters and results of similarity searches while a second table stores results of personal web construction.
Common Gateway Interface (CGI) is used to pass values throughout the application; only final calculated results are stored in the database.
3. Algorithm overview
Upon initial submission of a search set, ASE requests information from AWS and gets back a result set data structure containing an unspecified number of entities. The first ISBN is extracted, and a "similar to" query is sent to Amazon to get the first similarities list. The software then basically loops through similarity sets, with the search pattern determined by the user settings (deep vs. wide, number of searches). After all similarities are processed, the list is presented to the user. Each book has a link that will start a new ASE search, and a checkbox to indicate inclusion in the user's personal web. A simple overall duplication metric is calculated (# duplicates / # comparisons * 100.)
Once the users has selected the books to comprise his personal web, the "submit" command sends the list of selected books back to the application for cross-referencing. For each book submitted, the similarities are retrieved from Amazon and each is compared against all the other selected books to see how many matches are present. Again, a simple density percentage ( # hits / # tries * 100) is calculated. If there are fewer than ten items picked, the number of tries is adjusted to n * n-1.
The wide traversal algorithm was designed to move "across" Amazon's database. My thinking was that this would result in a more sparsely linked set of books. In fact, this algorithm consistently returns a higher percentage of duplicates than the deep search algorithm. Duplicates are cross references to books already encountered.
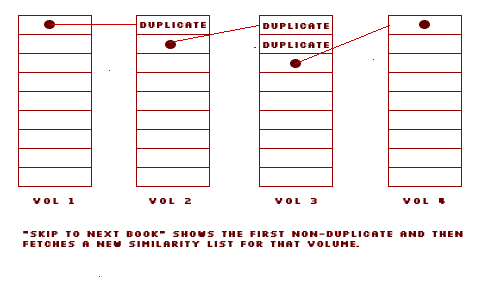
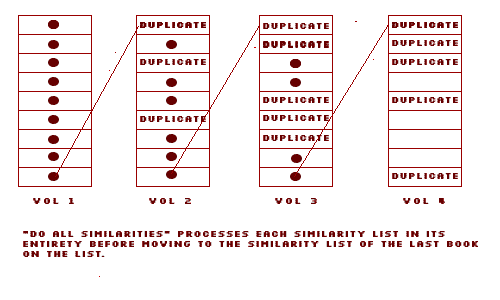
The deep traversal algorithm fully explores each similarities list returned from Amazon.com before moving on to a new one. A full tree traversal algorithm would get even deeper results, but that was not implemented. This approach returns a lower percentage of duplicates overall; by the time one is at the bottom of the list, the subject matter may have changed enough to get to a fairly fresh new list.
4. Restrictions and areas of improvement
No attempt was made to build this to industrial strength and there are many subtle and not-so-subtle areas where improvements could be made:
Obvious visual and navigational gloss is missing. A fairly advanced search screen is offered with many parameters; a simple Google-like interface could be used as well, where common settings are assumed or deduced from the input.
Algorithm for traversal should include a tree-traversal, where every node is deeply investigated.
The existing deep traversal algorithm is subject to a trap where the last reference on one list points back to the top of a prior list. While never encountered in real life, this looping would continue until the search depth had been reached.
Many bibliographic improvements could be made: using, for instance, the initially returned list rather than the similarity tree for the first book would make a big difference in how ASE works. It is too easy to get sidetracked by the reliance on the first search term.
None of the HTML has been validated or tested for accessibility; this is a hack, not a product.
The data retrieved from Amazon is not always reliable; at times, the wrong title is returned for a given ISBN, or it says similarities are not available for a search that should obviously return many items ("baseball" was returning a single entry one morning, for instance.). This tends to happen on wide search patterns with large search depths. I suspect it is due to bandwidth limitations they impose dynamically on the service available through their Web Services API. The specification says that a user is limited to one query a second. I make no attempt to throttle my requests and am certainly exceeding their stated access rate specification during wide search patterns where we move quickly from one similarity list to another. Doing deep search patterns is much slower, as all nine "similar to" titles in a result set are processed before the next request is made to Amazon Web Services.
The density calculation of the Amazon personal web is misleading for webs of more than ten documents; since my code only examines nine similarities per book, a web of more than ten would have potential links that will never be explored. The limit of nine similarities per book derives from the Amazon Web Services, where nine is the maximum number returned in a single request. It is possible to request additional "pages" of data, but that was not implemented. It is interesting to note that their website displays "Similar to" items in a three by three grid. It is possible that the output of Web Services was determined by the visual representation of a relationship on their website.
5. Conclusion
This was an easy program to write, but it took more time than I really wanted to spend on it. There are occasional irregularities and inconsistencies in its operation. I have not had time to figure out whether they result from bugs in my code, side effects of caching by the PHP library, or variabililty in Amazon.com's operation (or a combination of all three!)